
I Spent 5 Days In Programmer Hell To Prove Substack Fudges Stats
93 Paid Subscribers Who Didn't Exist: Much Like Substack Support

I spent no less than 5 days in ‘Programmer Hell’ after I went to datamine my own Stats in order to work out what The Daily Beagle Subscribers liked, and found an article with, supposedly, 93 Paying Subscribers:
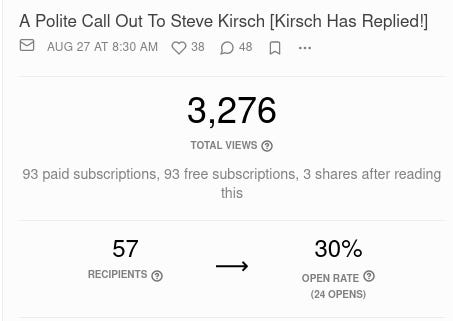
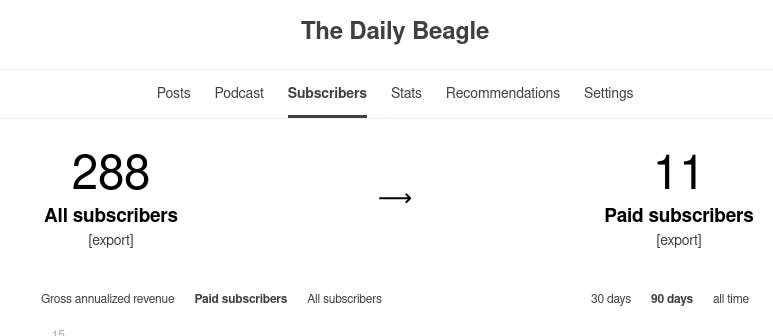
The only problem with this is the Substack Dashboard reported only 11 Paying Subscribers:
I had contacted Substack Support asking them to explain where the hell the 93 paying subscribers were?

Instead of answering the question, Substack support rudely ghosted me, and, hours later their website noticeably went down:

I double-checked the metadata of the various articles and found they had surreptitiously altered the stats without even answering my query (notice the missing 93 paying subscribers):

Checking other articles I found they had clearly done a hard reset of the statistics because a ton of articles - which I knew had more than one email recipient - were now reporting they had only been sent to 1 email recipient, which was literally impossible because they were on articles with more than 1 like (you need to be a free subscriber to like any post on Substack; ergo, a minimum of two recipients who both opened it are required):

I proceeded to call them out on this, which again, was met by stony silence, because Substack were apparently too embarrassed and hoped their screw-up would magically go away (no, it didn’t Substack):

Even now, the stats are still incorrect. It incorrectly claims I have 11 paying subscribers:

The only problem with this? Literally during my excursion, back on Tuesday, I lost a paying subscriber due to self-reported economic hardship:

Which means my paying subscriber count is mysteriously fixed to 11. According to Stripe, the payment processor, the actual number is at 10. A long way off from 200, and definitely not 93, and certainly not 11.

So, on top of trying to improve The Daily Beagle for Subscribers by working out the sort of topics people like, I decided I would spend time developing a bot to datamine my own metrics to prevent Substack pulling another fast one. And it was hell.
5 Days In Programmer Hell
If you’ve wondered where the regular news articles have been, I have literally been stuck in Programmer Hell with Selenium, a tool for automated browsing. I couldn’t report on the events without a conclusion, and did Selenium do everything it possibly could to stop me from succeeding.

It refused to accept any XPATH references for a specific SVG child node. But only the SVG node. Free pass for any other type of node, apparently.
I tried over 20 different variations waiting between 30 seconds to a minute for it to crash on each one. It was tedious, and boring. I got so bored I somehow stumbled across a video giving advice on ‘Bad Driving Habits’ where the guy has his hands off the steering wheel in what can only be described as cosmic level irony:

I ultimately did a huge programming no-no and hardcoded the SVG reference by numerical order because after 8 hours at staring at puked out Selenium error messages which are unreadable colon-number spamfests at the best of times, I had enough of playing ‘guess which XPATH I like this time’ with Selenium.
Then I found it picking up elements that didn’t exist in nodes that weren’t relevant, watched as Selenium puked even more ‘no I don’t like this XPATH’ error messages at me where it flip-flopped between accepting XPATHs that started with “//” (root), some that had “.//” (relative to this) and others that had “./” (also, uh… relative to this? This shouldn’t even be valid).

It had no rhyme or reason. It did not matter if you passed a child relative reference to the root browser node, or a root reference to a parent, Selenium would sometimes accept those (even though it really shouldn’t). Selenium just cherry picked which XPATHs it did or did not like. Annoying things like logic and consistency would not halt Selenium.
Meanwhile the world was suddenly popping off with interesting stories like the Nordstream pipeline sabotage, rumours of Xi being overthrown and then not in China, and Jet Stream teleporting Hurricanes attacking Canada. All stories I would have loved to have written about on the implications.
‘Can’t stop, gotta prove metadata stats’. The world ending wasn’t going to stop me from finishing code or putting some dirt in Substack’s eye.

Selenium Fought Tooth And Nail
Even as I cracked the XPATH references and created bypasses, and at the same time fought with government departments doing stupid bureaucratic pointlessness via email and phone over healthcare, Selenium did not just give up.
Selenium then screwed up datasets instead. Random commas mangled integer conversions. Here, have a random HTML tag for no reason. ‘Sometimes there, sometimes not’ elements would fade in and out of existence and had to be tested for in try-except clauses like Scooby Doo looking for the scary ghost behind each door.
Sometimes Selenium wouldn’t throw any helpful error messages at all, like a gang member at a no-snitch convention. But I was a Veteran of JavaScript, the language King of the ‘tell you nothing no-error messages’. I wrote so, so, so many print statements, randomly stabbing in the dark at nothing to work out what had broken this time. Warm. Warmer. Cold. Freezing. Hot.
Hide And Click
You had to scroll down in order for elements to load due to the ‘infinite loading’ UI design from hell so many websites use - Substack included. Efficient pages are uncool man.
I got my first dataset which was completely mangled like government unemployment stats, and repeated the same number many times like a politician trapped in an infinite loop. Something was wrong. Wrong element references fixed. Some elements literally had no number, so you had to default to 0. I was losing hair over the tedium of these papercuts in personal time.
Then I found out Substack hid information unless you explicitly clicked on it. So, not only did the code have to scroll down and detect the end to load all the elements, but it also had to click on the elements individually.
Playing Dumb
Selenium won’t just clever click stuff though. No, no, Selenium has to actually see the element to click it. So it also had to scroll up, then scroll down again and expand each metadata segment, jumping to each element.
Scrolling broke and got trapped in an infinite loop. Then it scrolled but Selenium still couldn’t ‘see’ the element. Then I centred the element with a ‘it is right there, in front of you!’ moment. Selenium just outplayed me again by clicking on the article link instead of clicking to expand the metadata for the article, before crashing again.
I took a “break” by perusing the news to see if there were any interesting leads for possible Daily Beagle stories, and probably tried to re-view the same data source 10 times through-out.
Finally, scroll-clicking worked. Until it didn’t. Selenium then just skipped random elements it didn’t feel like clicking on, butchered the metadata and crashed in a firey ball of ‘f**k you’.
In revenge I trapped Selenium in an infinite loop of ‘whilst there are unexpanded posts, you are going nowhere’ and watched as it frantically jumped around the list like a seizure trying to catch the ones it missed.

Then it played hide and seek with another no-snitch session on another bug, which I used numbered flags to work out where it was falling over and fixed.
So, What Do The Stats Tell Us?
Finally, after the code worked, it gave me a CSV with the Stats. I uploaded a copy in .ods format here if any readers wish to peruse.
Firstly it clearly shows Substack has indeed fudged the stats. If we look at these contigious articles (older at the bottom, newer at the top), we see in the ‘free’ column I gained free subscribers, but the recipient count did not increase for the subsequent articles:

We can also see a similar discrepency if we tally up the number of reported free subscribers:

‘177’, despite the fact that we have 268 recipients (as of our most recent article, In Defence Of Incels):

This means 91 recipients have been yeeted into the void by this surreptitious stats fudge.
On a lighter note amongst this tomfoolery, the top ten articles people seem to like upvoting are ones that discuss other popular people, with the Steve Kirsch article hitting a whopping 38 likes:

Our top ten most viewed articles are the ones I’ve been pushing in various places to draw attention:

Our top ten most shared articles seem to relate to topics that contain or reference surprising or unusual facts:

And our top nine (we don’t have enough paying subscribers for top ten) paying subscriber articles seem to be ones that resonated personally with people on some level:

This gives The Daily Beagle some predictive power of how well articles will perform depending on their content and context. Assuming, of course, the stats aren’t fudged.
This article is likely to see a high number of shares but little else as it contains a surprising fact people didn’t know.
The Stats also tells us people want high visibility articles that teach them unusual, surprising facts that personally resonate with them. We’ll aim to deliver. Apologies for the delay. Normal train services will resume shortly.
Edit: Since publication of this article, Substack Support suddenly got back in touch to say that there was a bug in the dashboard.

Hmm. I have raised bug issues before and got a response same day. Did it really require I wait 3 days and publish an article to get a response?
Daily Beagle’s is a long way off from becoming financially viable, consider becoming a paying subscriber today, and put some dirt in Substack’s eye!
Want more people to learn what you’ve learned? Be sure to share!
What do you think about Substack? Our articles? Got any suggestions for improvements? Any articles you really like?
Underdog, please pass this info on to Meryl Nass (she's a substack writer too). Because she was wondering about this, and maybe bec substack knows she has such a substantial following with high publicity within covidtruthworld, they immediately had a developer fix it for her and write an explanation that they had recently processed an update and thats why it happened and that it was a one-off etc., So maybe that was subterfuge. Anyhoo, yeah.... maybe the cabal minions are using substack to gather up the info on all of the dissenters. They keep warfaring us to make us feel we have no where to go and nowhere to trust in.
Who can you trust these days? Not the WHO 'cos it's 'owned, controlled and manipulated by Bill Gates who once said "The most lucrative investments I've ever made = VACCINES!" He didn't say "even if they are useless, dangerous and can kill people". 'LIABILITY' must return to Vax makers - stop expecting gullible Governments to pick up the tab for your 'LICENCE TO KILL' attitude towards safety and inherent dangers within their unsafe products. Mick from Hooe (UK) Unjabbed and ready to fight.